RT2-X place apple into top drawer
Octo-Base put eggplant in basket
Octo-Small put spoon on towel
RT1-X close bottom drawer
Octo-Small stack green block on yellow block
RT1 move redbull can near orange
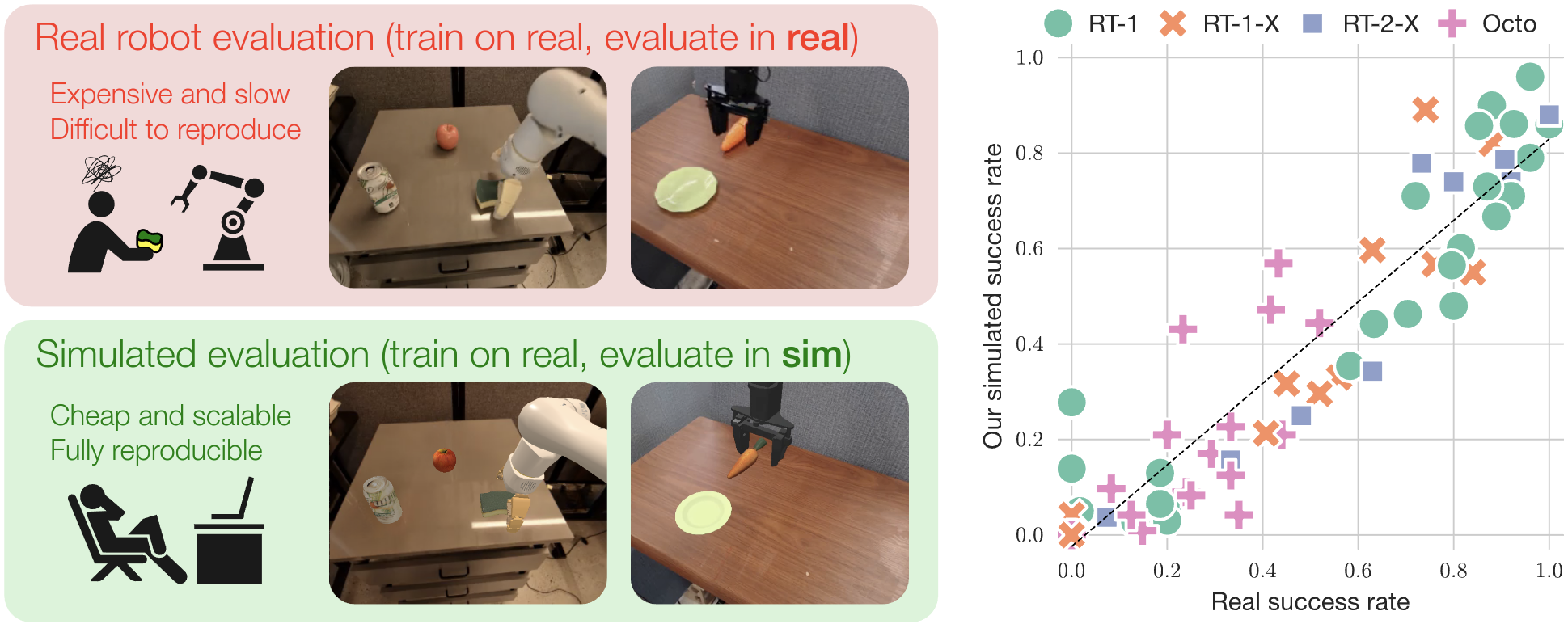
The field of robotics has made significant advances towards generalist robot manipulation policies. However, real-world evaluation of such policies is not scalable and faces reproducibility challenges, which are likely to worsen as policies broaden the spectrum of tasks they can perform. In this work, we demonstrate that simulation-based evaluation can be a scalable, reproducible, and reliable proxy for real-world evaluation. We identify control and visual disparities between real and simulated environments as key challenges for reliable simulated evaluation and propose approaches for mitigating these gaps without needing to craft full-fidelity digital twins of real-world environments. We then employ these approaches to create SIMPLER, a collection of simulated environments for manipulation policy evaluation on common real robot setups. Through paired sim-and-real evaluations of manipulation policies, we demonstrate strong correlation between policy performance in SIMPLER environments and in the real world. Additionally, we find that SIMPLER evaluations accurately reflect real-world policy behavior modes such as sensitivity to various distribution shifts. We open-source all SIMPLER environments along with our workflow for creating new environment to facilitate research on general-purpose manipulation policies and simulated evaluation frameworks.

We introduce SIMPLER, a suite of open-source simulated evaluation environments for common real robot manipulation setups. All environments expose a uniform Gym API. Additionally, we open-source policy inference code (e.g., RT-1, RT-1-X, Octo) for real-to-sim evaluation, and we provide a detailed guide for evaluating new policies and creating new evaluation environments. All environments can be imported with a single line of code and can be interacted with through a standard Gym interface.
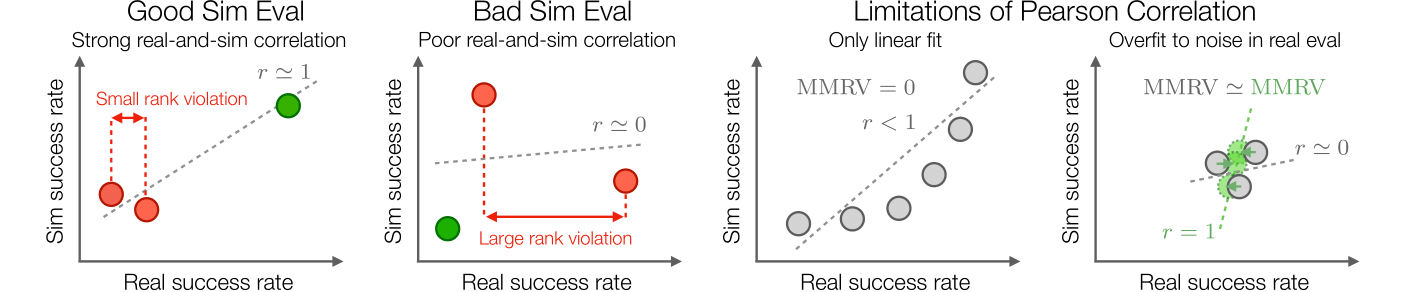
An effective & useful simulation-based evaluation should demonstrate good correlations in policy ranking & performance with real evaluations.
To measure such correlations, one can apply the traditional Pearson correlation metric ("r"), but it has the following limitations: (1) Pearson correlation only assess the linear fit between real-and-sim performances, while for simulated evaluation we don't necessarily need linear correlations, as long as sim eval reflects real-world performance improvements between different policies (middle-right); (2) Pearson correlation does not reflect the range of values it is computed over. For policy sets that perform closely in real (far-right), Pearson r may change drastically based on small real-world performance differences, which can often be attributed to the inherent noise in real-world evaluations.
Thus, we introduce the Mean Maximum Rank Violation (MMRV) metric (lower the better) to better assess the real-and-sim policy ranking consistency. The key underlying quantity is the rank violation between two policies, which weighs the significance of the simulator incorrectly ranking the policies by the corresponding margin in real-world performance. MMRV then aggregates the N^2 rank violations by averaging the worst-case rank violation for each policy.

Visual discrepancies between real-world and simulated environments can comprise a distribution shift that adversely affects a learned policy’s behavior, rendering simulated evaluation unreliable. Our goal is to match the simulator visuals to those of the real-world environment with only a modest amount of manual effort. Our proposed Visual Matching consists of (1) green screening, i.e. segmenting out interactive simulated assets and overlaying them onto real-world backgrounds; and (2) texture matching, which involves projecting real object textures onto simulation assets and tuning robot arm colors using real videos.
The goal of mitigating the control gap between simulated and real-world environments is to ensure that policy actions executed in simulation yields comparable effects on the robot’s end-effector as those observed when executed on the real robot. We perform system identification (SysID) for closing the control gap between real and simulated environments on a small sample of trajectories from the real world dataset.
Real World Rollout
Control without SysID
Control with SysID
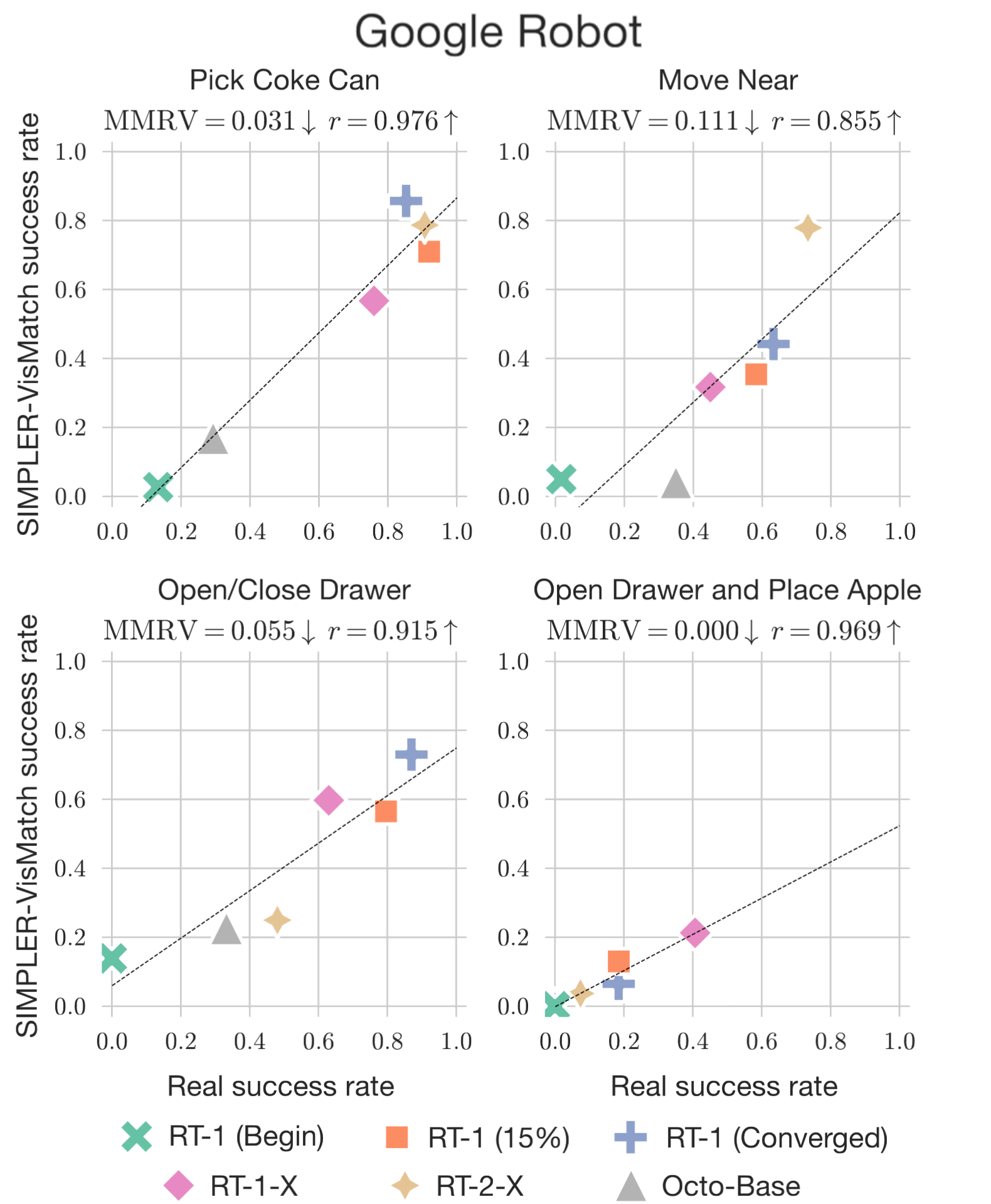
SIMPLER can be used to evaluate diverse sets of rigid-body tasks (non-articulated / articulated objects, tabletop / non-tabletop tasks, shorter / longer horizon tasks), with many intra-task variations (e.g., different object combinations; different object / robot positions and orientations), for each of two robot embodiments (Google Robot and WidowX).
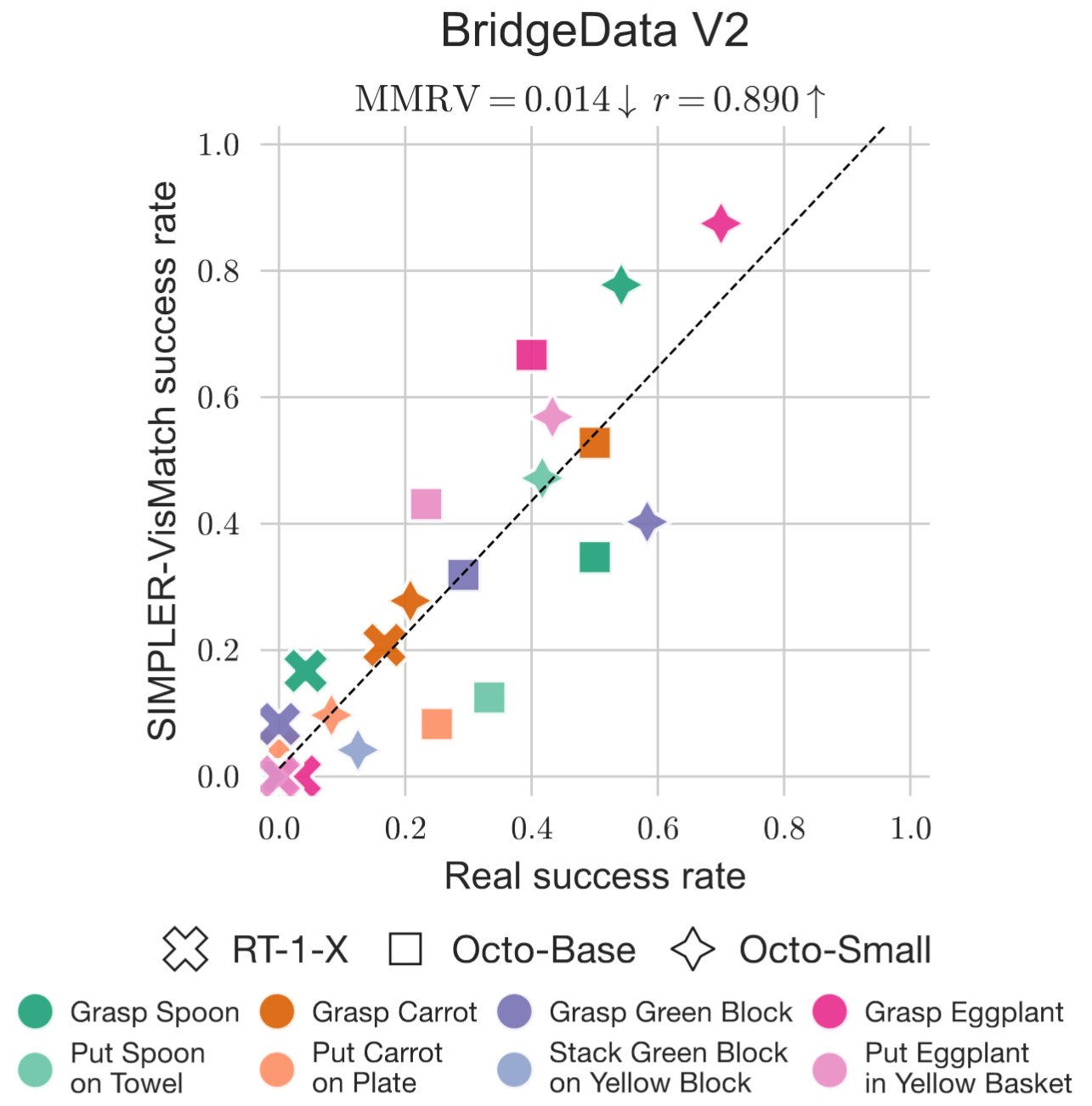
SIMPLER can also compare the performance of different policies and perform checkpoint selection. Policy performances evaluated in SIMPLER have strong correlation with those in the real world (illustrated by low MMRV and high Pearson r in the figures below).
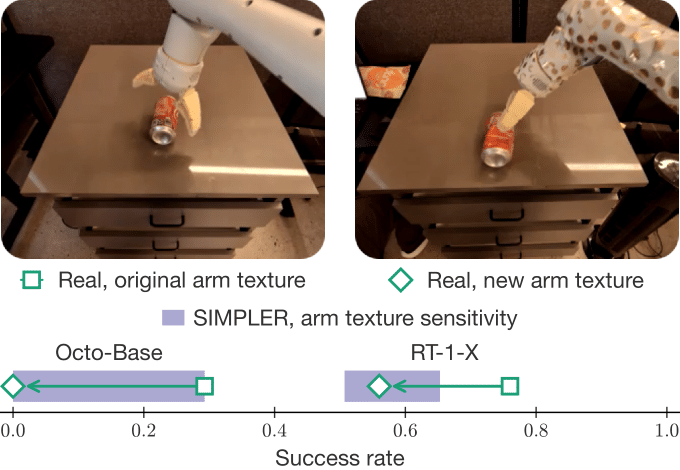
SIMPLER can be used to analyze the policies' finegrained behaviors, such as their robustness to common distribution shifts like lightings, backgrounds, camera poses, distractor objects, and table textures (fig: left). The findings from SIMPLER are highly correlated with those in the real-world (illustrated by low MMRV and high Pearson r). Additionally, SIMPLER can predict policy behaviors under novel distribution shifts, such as changes in arm textures (fig: right).
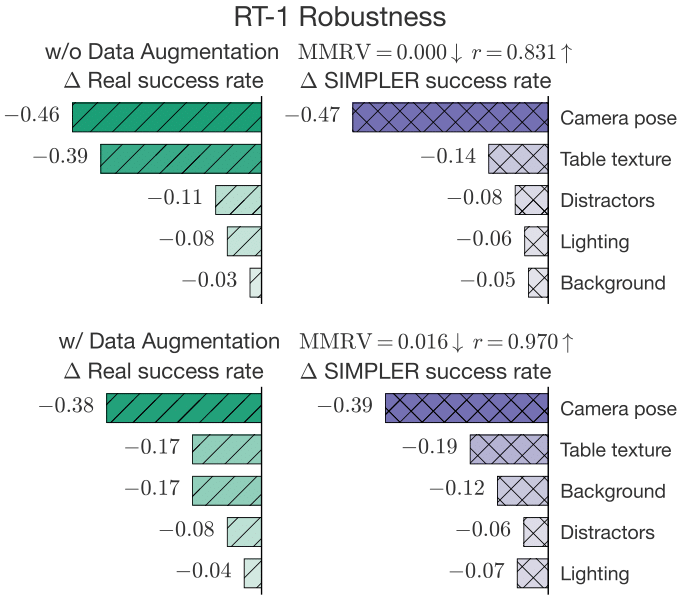
SIMPLER yields a strong correlation between real-world and simulated performance across ∼1500 evaluation episodes (from each of real and sim).
Here we illustrate a few paired evaluations in real and sim.
(Google Robot control frequency: 3Hz; WidowX control frequency: 5Hz; Each video frame corresponds to a control step)
@article{li24simpler,
title={Evaluating Real-World Robot Manipulation Policies in Simulation},
author={Xuanlin Li and Kyle Hsu and Jiayuan Gu and Karl Pertsch and Oier Mees and Homer Rich Walke and Chuyuan Fu and Ishikaa Lunawat and Isabel Sieh and Sean Kirmani and Sergey Levine and Jiajun Wu and Chelsea Finn and Hao Su and Quan Vuong and Ted Xiao},
journal = {arXiv preprint arXiv:2405.05941},
year={2024},
}